Shawn Mahaney – Lead Analyst
INTRODUCTION
I was looking in the last few month at new computer hardware. Ok, in actuality I am always looking at new computer hardware. It’s where I make my living, and watching it evolve and perform can be pretty cool.
The main workstation PC in my personal office is, and has been for too many years, a collection of old and new parts stuffed into an ATX case that’s seen multiple upgrades of every sort. In 2012 it got a motherboard mounting the living legend Intel i7-3770k processor (quad core, 3.5 GHz). The system got set up with 16 GB of RAM, which was generous at the time. But Stone Lake has been tackling some larger jobs, and asking more specific questions of the simulation tools. We’re seeing bigger meshes and using more contact and articulation – more memory is needed.
That old 3770 is still quick enough to crank through tough jobs in a reasonable time, but it’s chained to DDR3 memory, at 667 MHz. Recent experience has led me to believe that RAM speed is the bottle-neck for some of our work, which often needs 64 GB systems. So I was determined to get a quad-channel RAM system, and decided I would benchmark a few systems to see for myself just what matters for the kinds of problems we solve.
There are many computer benchmarks to pick from. Few that I’ve seen deal with large data sets, even Solidworks simulation benchmarks. So I picked a couple problems which take up a decent bit of memory, enough to need a 16 GB system. Solidworks simulation run times for them are compared here to raw benchmark results.
THE STUDIES
The first study is of a die cast machine die holder. This multi-ton block of steel holds together all the die pieces for a high pressure metal casting process, under about 6 million pounds of clamping force. It has dozens of cooling lines and clearance passages for myriad other fluid and mechanical functions. It is simplified somewhat from the final CAD file, but we usually lean toward leaving in detail. When the model looks more like the real thing, there are fewer doubts for the client.
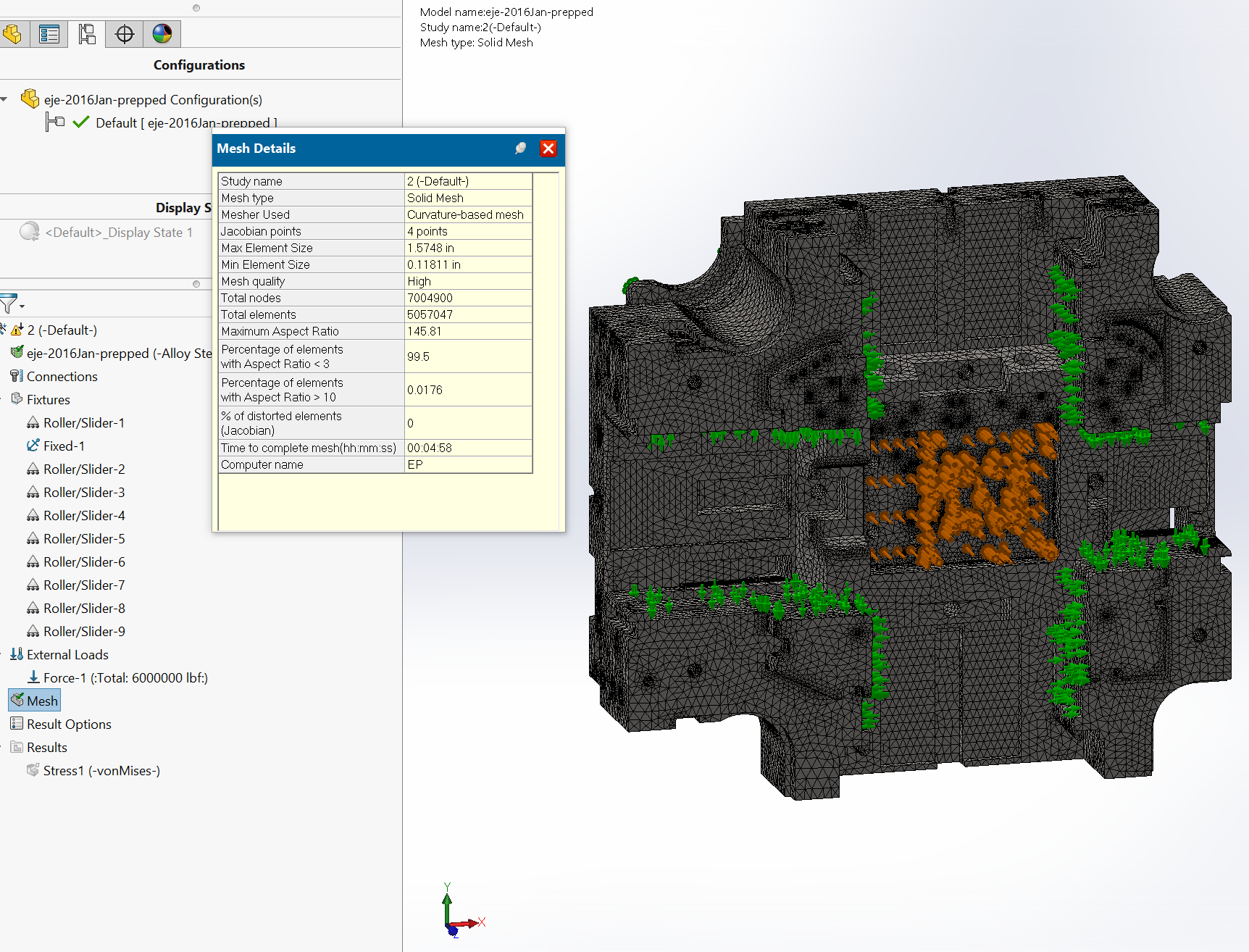
The mesh comes out over five million elements. Mesh creation peaks using over 7 GB of RAM. An iterative solver must be used to fit the problem in a 16 GB machine, using almost 10 GB.
The second Solidworks study is smaller, but uses high accuracy contact and a relatively fine mesh. Running the Intel direct sparse solver it will make more use of raw CPU speed and multi-core processing.
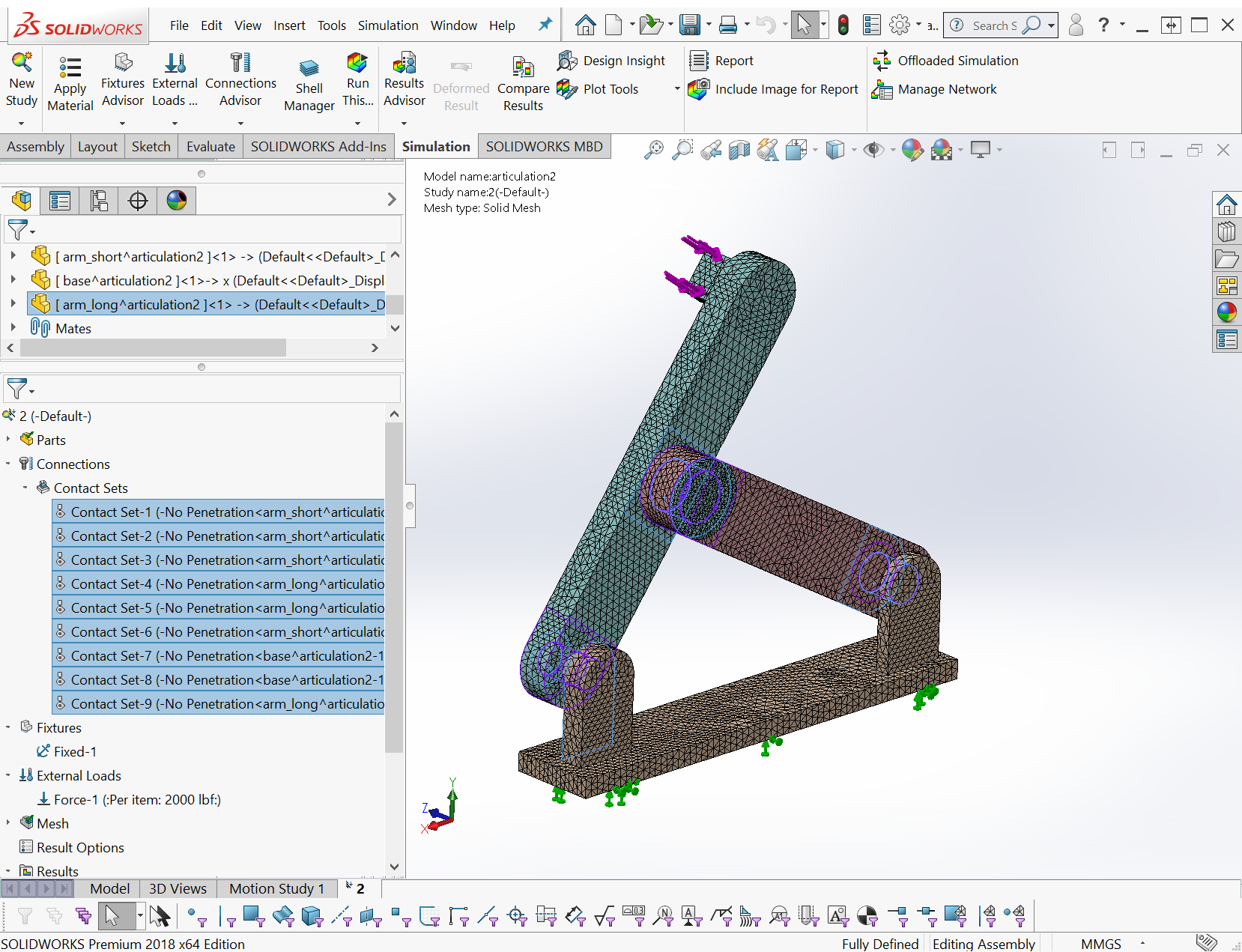
Mesh generation time for this study is minor. During the run it needs about 3.3 GB of memory.
The last study was run only on the newest box. It’s the real memory hog, taking over 30 GB of RAM to run through its 750,000+ elements. The direct sparse solvers are not compiled for much larger problems. To make this model an existing study was used with the element count jacked up much higher than necessary.
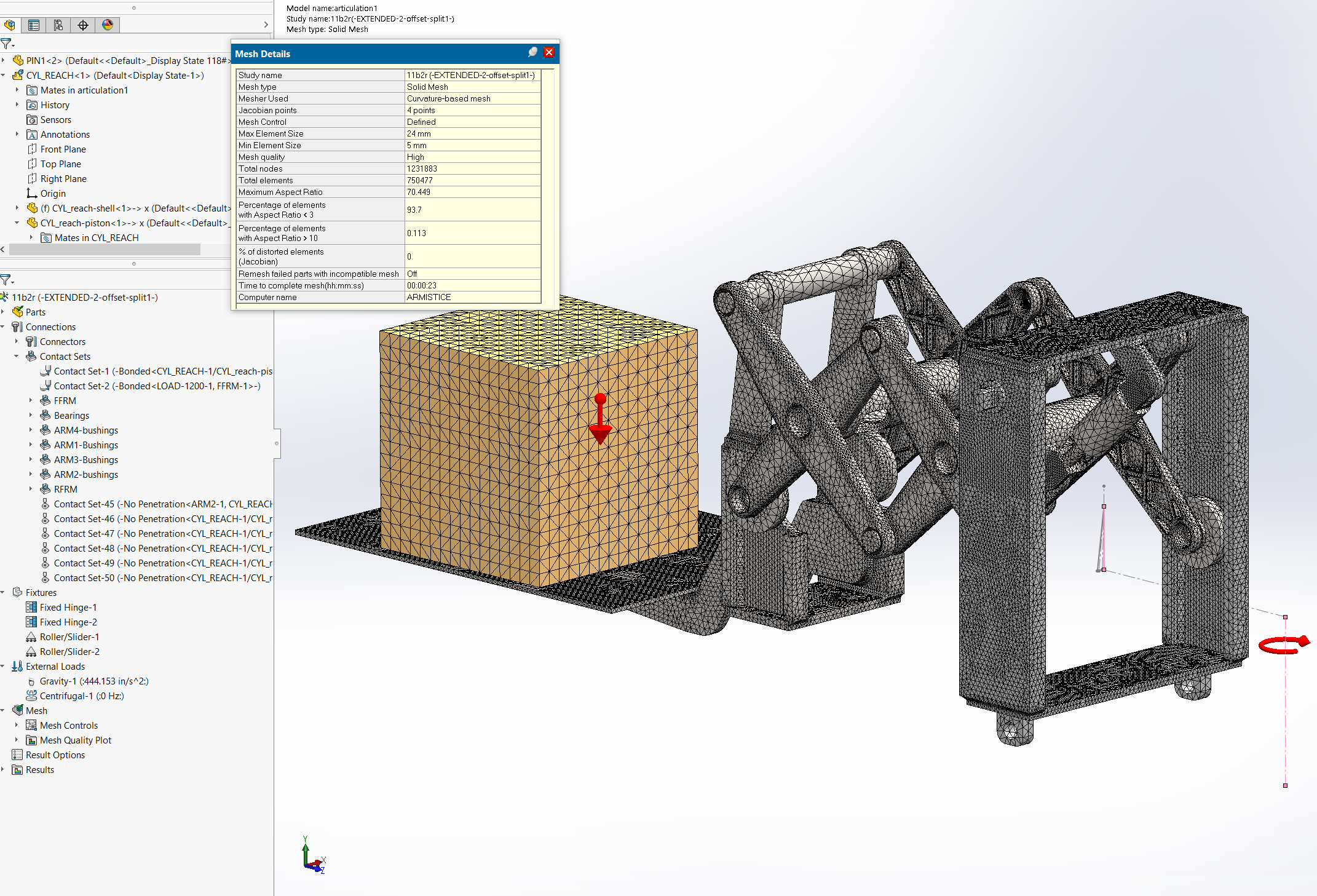
Let me reiterate – I KNOW THE MESH IS OVERLY FINE. The model gives usable results at half the mesh size. [Incidentally, if you think this is a large problem – note that similar pantograph mechanisms we’ve studied fit inside telescoping lifts, and we are routinely simulating them all together in full free contact.]
THE BENCHMARKS
I’m most familiar with the benchmark suite from Passmark. Their Performance Test 9.0 is used to generate a stack of comparable data.
THE SUBJECTS
A selection of Stone Lake’s own system were used, plus some borrowed time on two partner’s workstations.
– custom, 2012: i7-3770k, 4 core at 3.5 GHz, 667 MHz DDR3 RAM
– Dell T3600: Xeon E5-1650, 6 core at 3.2 GHz, 667 MHz DDR3 RAM
– Lenovo Y700 laptop: i7-6700HQ, 4 core at 2.6 GHz, 1067 MHz DDR4 RAM
– BOXX Apex2: i7-6700K (overclocked), 4 core at 4.4 GHz, 1067 MHz DDR4 RAM
Our new system was set up with a shiny new Intel i7-9800X processor, with quad-channel memory. It was set up bone stock, then given a mild overclock treatment.
– custom, 2018: i7-9800X, 8 core at 3.8 GHz, 1067 MHz DDR4 RAM
– custom, 2018: i7-9800X (overclocked), 8 core at 4.2 GHz, 1333 MHz DDR4 RAM
Other components in the systems are decent parts contemporary to the builds. The new box has two PCIe SSDs in a RAID 0 array, which is really screaming fast, but not much to do with the purpose today.
THE RESULTS
System specs, raw benchmark results, and Solidworks run times appear in the table below (click to expand).
Also shown are charts of the times against selected benchmark values.
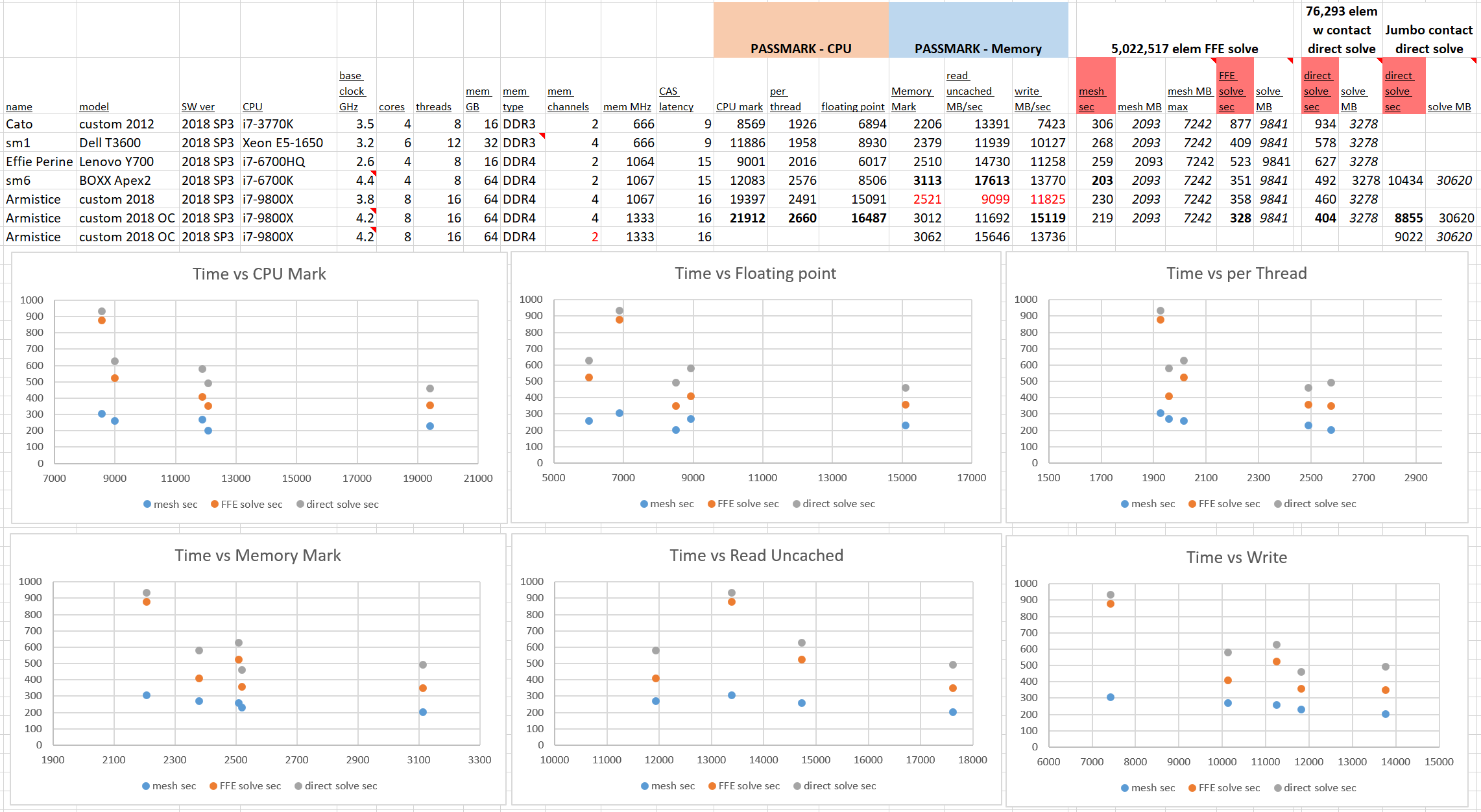
Obvious trends do not jump out from the charts. No one of the selected benchmarks is especially well correlated to Solidworks performance. In general it can certainly be said that newer hardware is better, but the expected leap in performance from quad channel memory just isn’t there even for the larger problem.
[A few good studies have been done of interest to us – Look at the great cores-vs-frequency study from Puget Systems. That article drove our choice of an 8-core system with relatively high clock.]
Since this isn’t a clean controlled study, where parameters are varied one at a time, we shouldn’t expect nice monotonic graphs every time, but the jumps here are curious. The first observation is that the memory performance of the newest system is pretty poor, in most benchmarks. The full set of memory tests appears below.
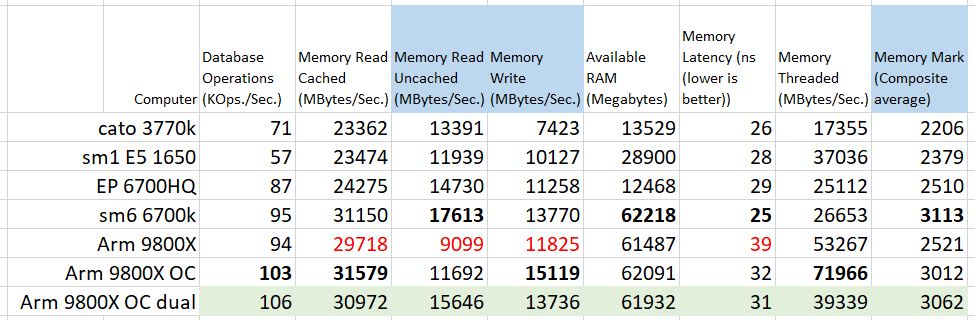
One certain thing is that the BOXX system’s memory performs fantastically well. I didn’t get a chance to dig into the BIOS, only getting what specs CPU-Z would report. I suspect some effort went into the memory timings at BOXX. As for my new build, it got whatever Crucial had preloaded in an XMP profile.
The higher core count chips excel in “threaded” memory access. This test involves the CPU cores directly in some way (I’m at the limit of my expertise here), so the result fits that one nugget of knowledge. I can’t say how much any of the memory benchmarks really lead to better Solidworks simulation performance.
It may be that memory speed was the bottleneck on the 667 MHz DDR3 systems I was using a while back. It looks like RAM can keep up plenty well these days. But for one last check I set up the “jumbo” study and moved DIMMs in the new system to dumb it down from quad-channel to dual-channel memory.
Dropping to dual channel the run time of our 31 GB jumbo run came in a whole 1.9% slower.
I can say that the CPU is still king. Full processor benchmarks follow.
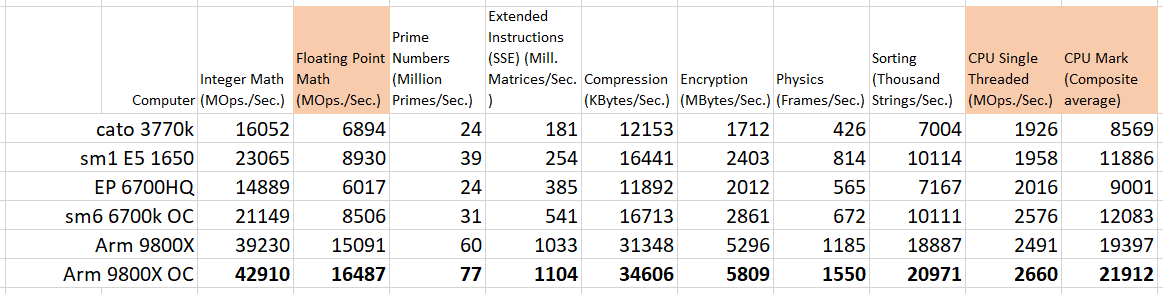
The ultimate goal is to get good run times on big problems. For a final comparison the “jumbo” run was done on the two year old BOXX system. The new system, with comparable overclocking, comes in over 15% faster. I’m pretty happy.
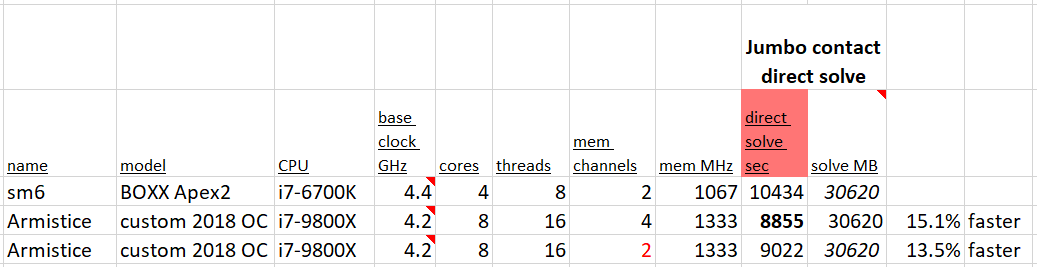
Among modern core architecture (i.e. Skylake) chips, raw clock speed gets us the fastest meshes. A combination of clock and core count brings analysis results sooner. And since I think most users sit and wait for meshes to be made, as opposed to doing other things during the analysis, in Timoshenko’s name buy the fast chip!