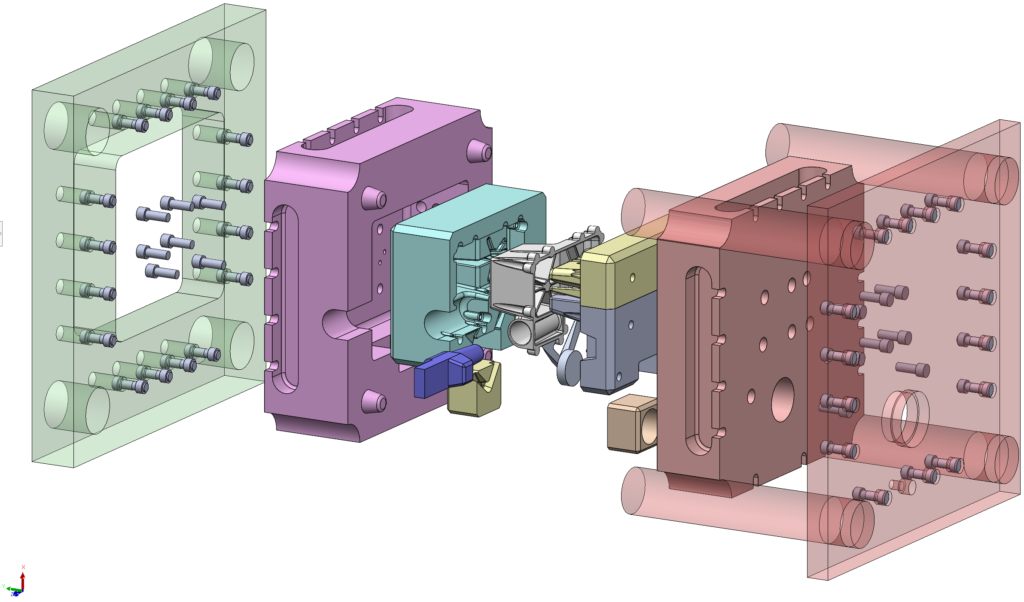
It’s been a while since we ran new benchmarks on simulation problems. It also took Intel a well-documented long time to get a new architecture and process on the market. After many hours checking new processor release dates and rumored specs, while waiting on studies to run, we finally got a new desktop system. We were holding out for a “4th Generation Xeon Scalable” rig, but settled on a “12th Generation Core” system at an attractive price.
High level specs on this new box include an Intel Core i7-12700k processor, 2 TB NVMe main drive, nVidia RTX 3080 graphics, and 128 GB of DDR5 memory. After setup and a quick stress test benchmarks were the first order of business. Again standard Passmark tests were run and then the same sim models we ran in Solidworks 2018 were run in Solidworks 2020.
The old benchmark article, from December 2018, can be found here.
Subject systems still available to bang on are the 6th generation 6700K, a 9th generation 9800X, and of course the new 12700K. The basic specs and synthetic benchmark results are tabulated below.
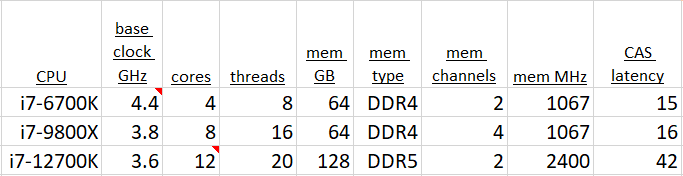

The 12th generation chip, finally made on a true 10 nm process, shows a great leap in raw performance. Gritty details can be found all over the internet about the details of the new chip. We noted that they took advantage of the smaller process to pack larger local caches into the die. High level Intel documents talk about added cleverness in ordering and streamlining operations. Busses to memory and storage are faster and wider. Then there’s the whole P-core and E-core hybrid design added to the system.
But the real test of all that brute power and cleverness is in performance on real problems. So we return to the same problems as before.
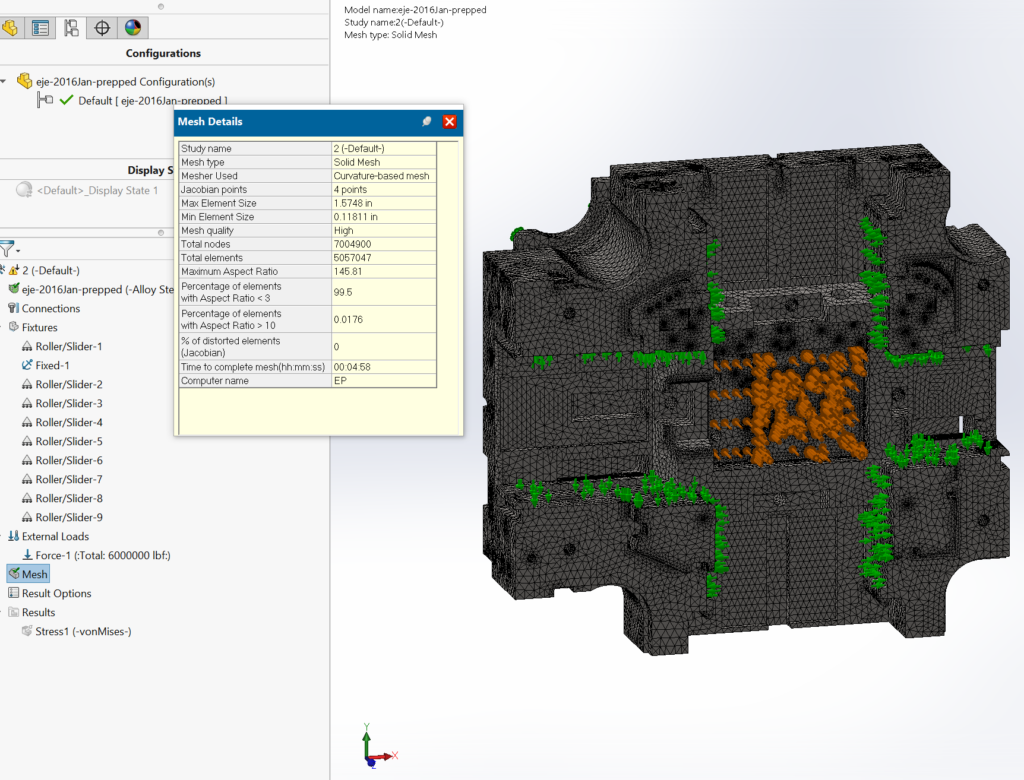
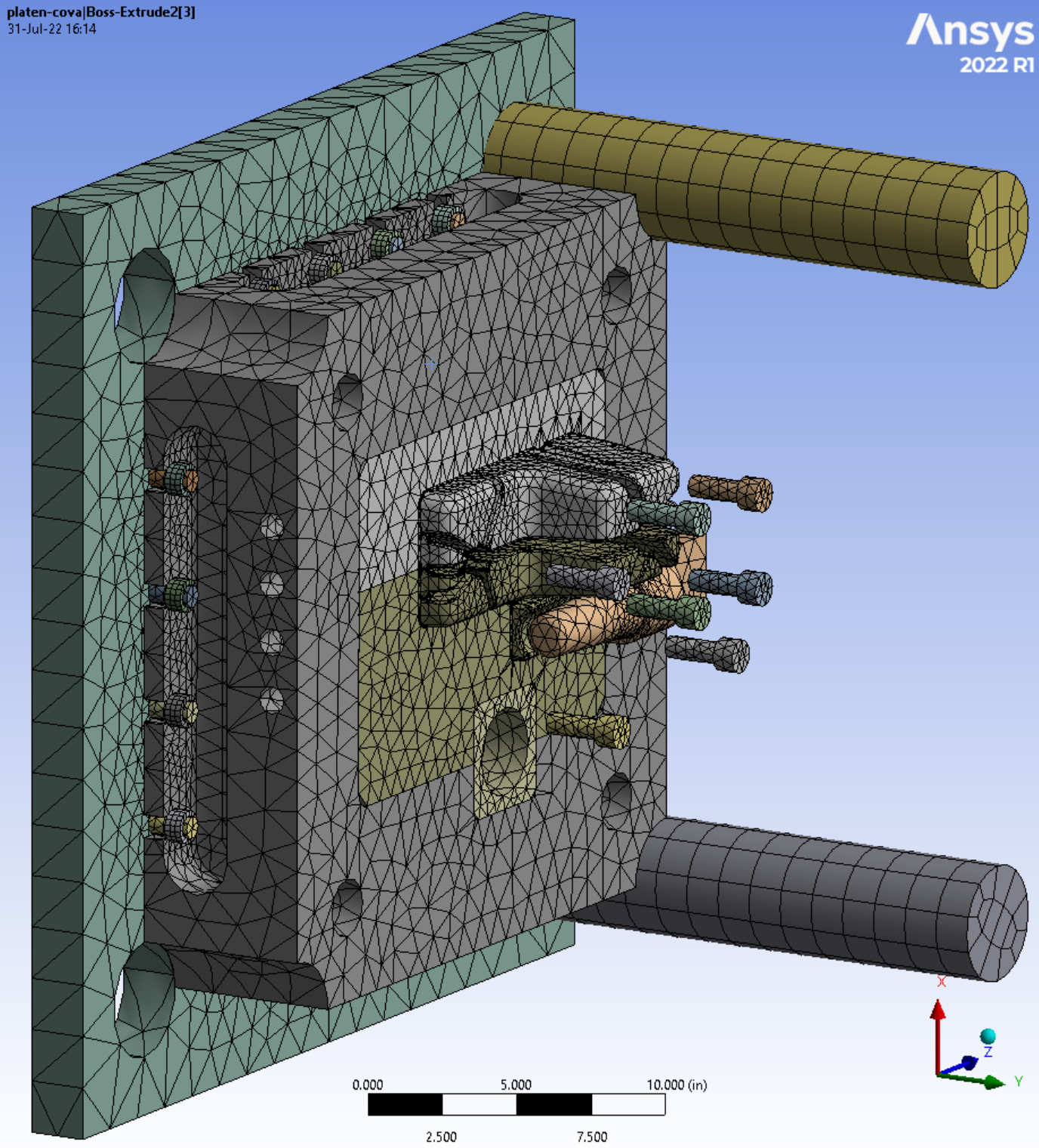
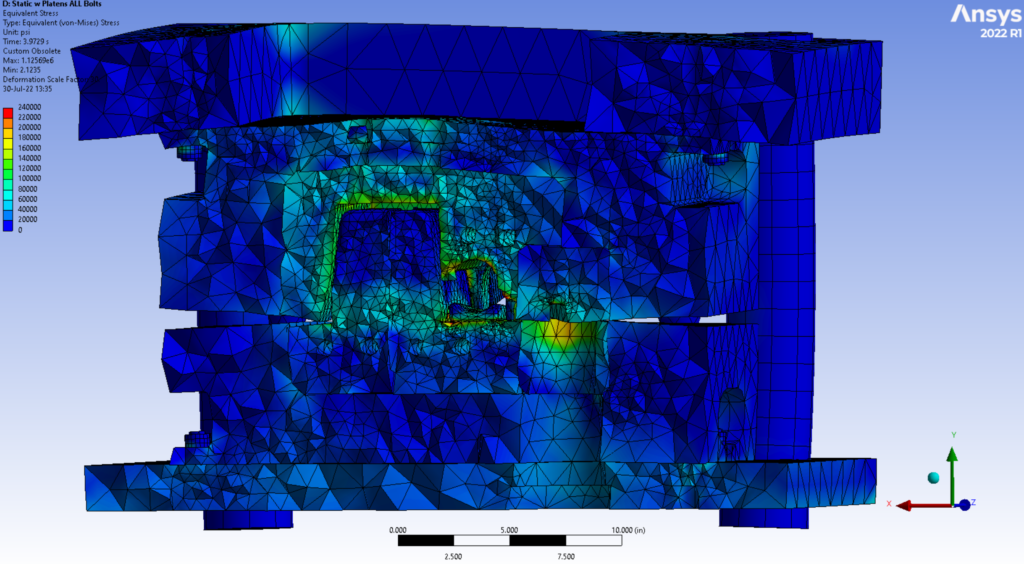
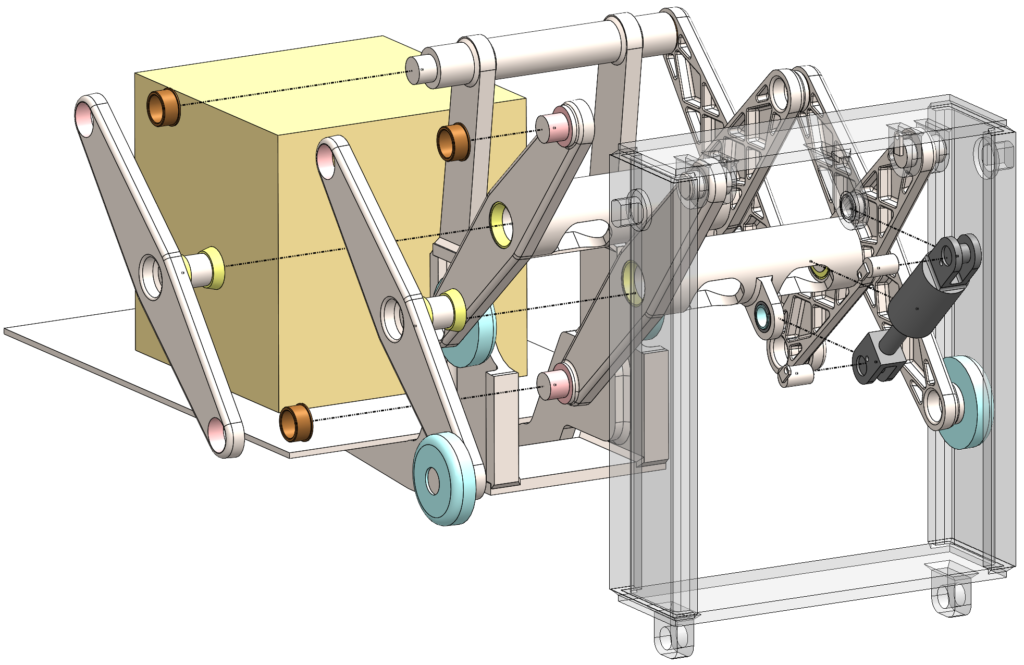
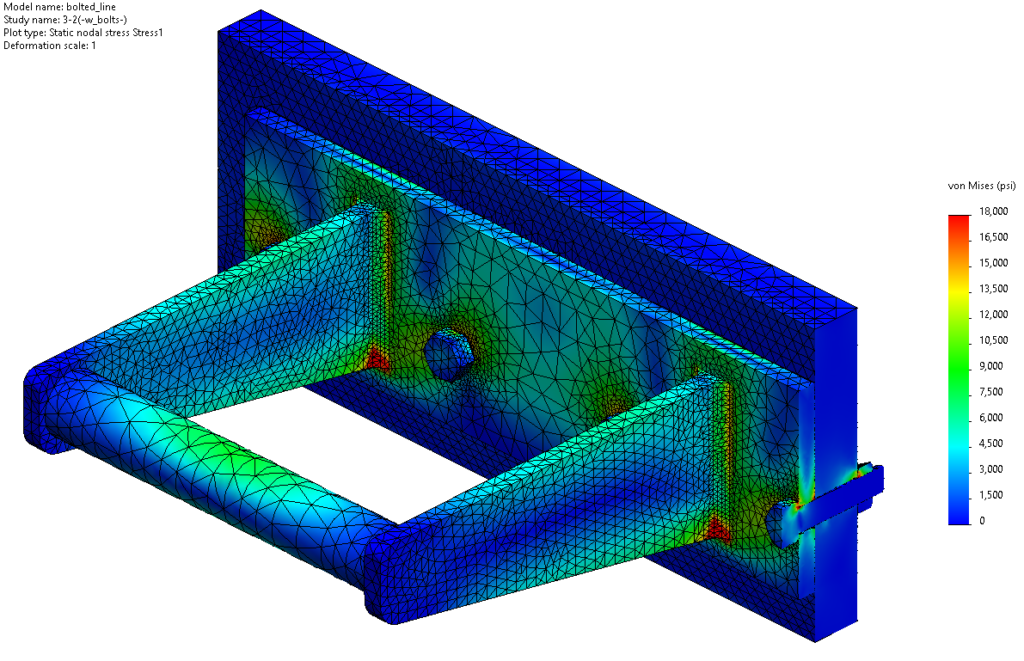
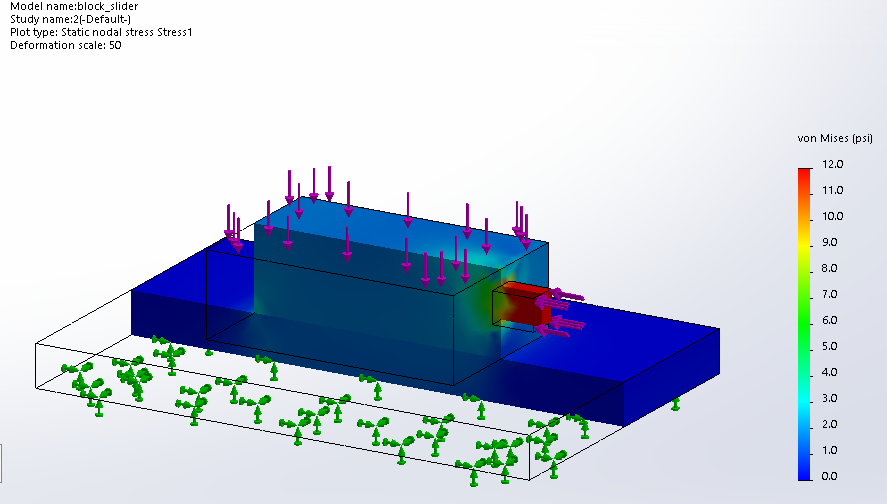
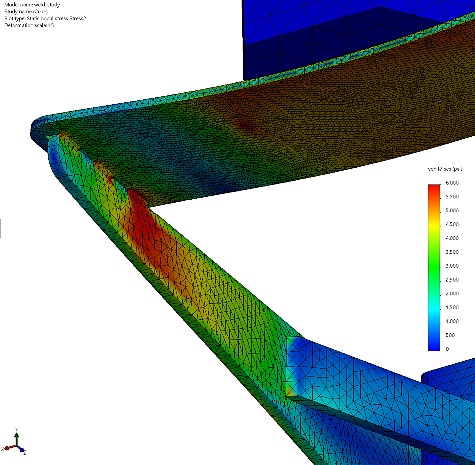
This large solid block with lots of internal detail is used to check mesh speed and solve time with an iterative solver.
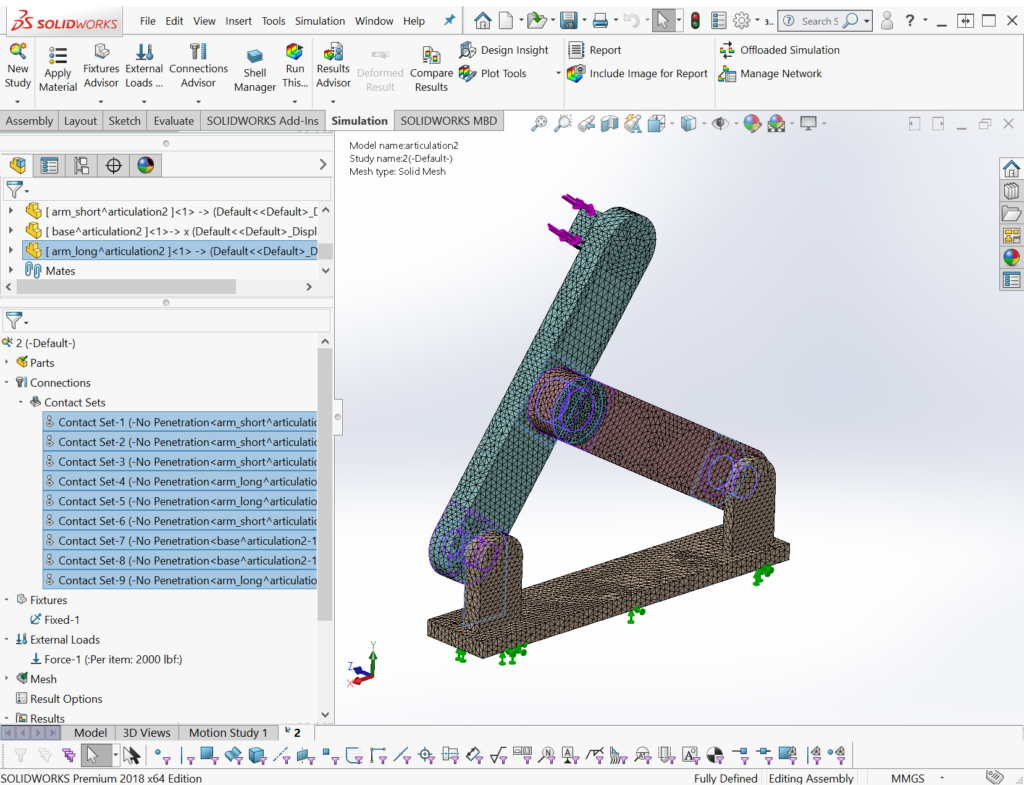
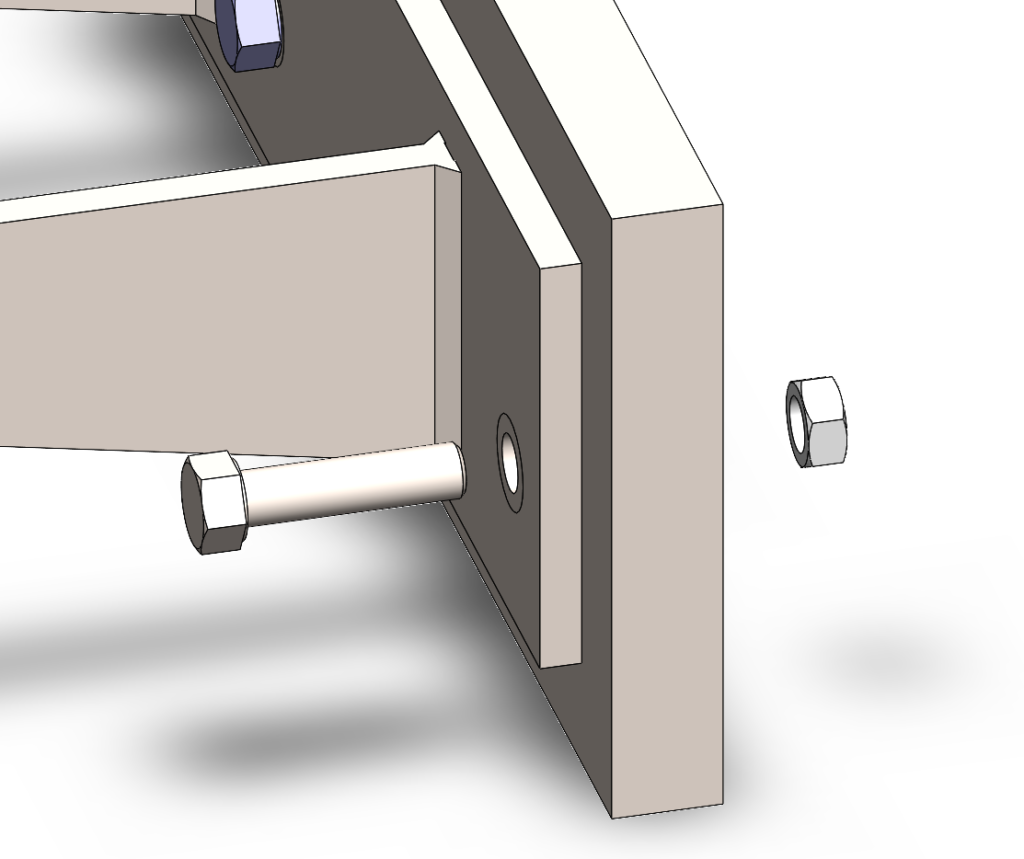
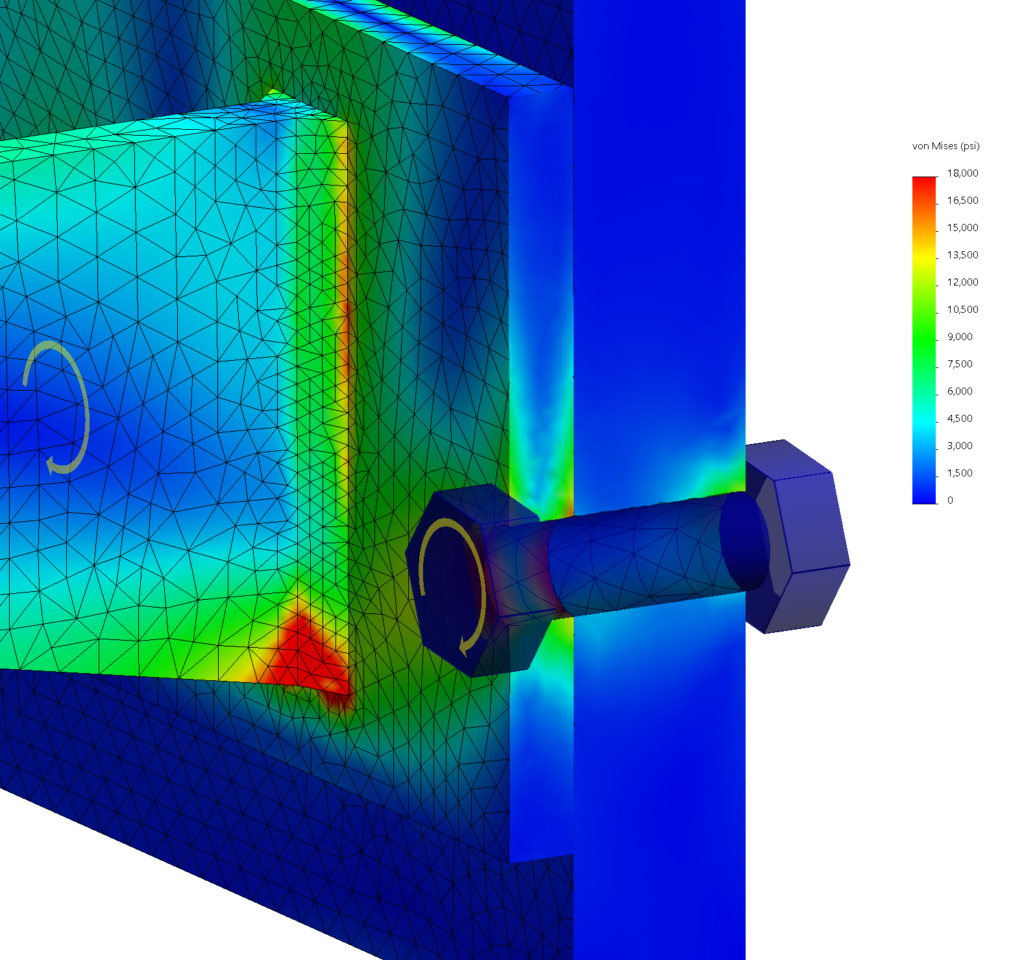
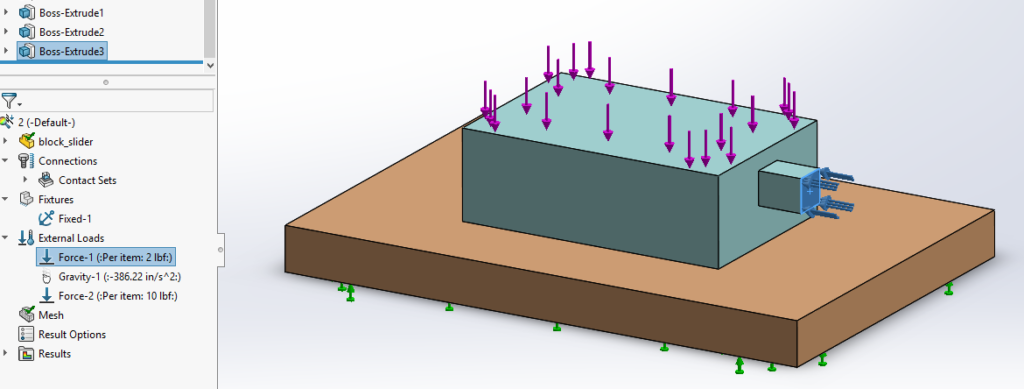
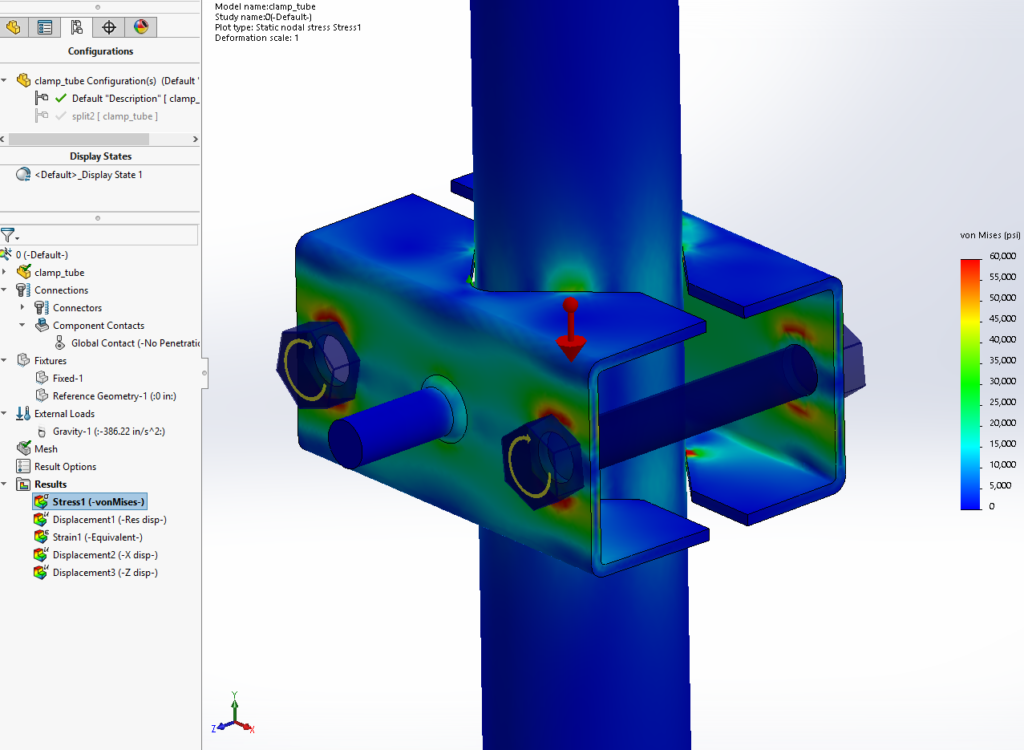
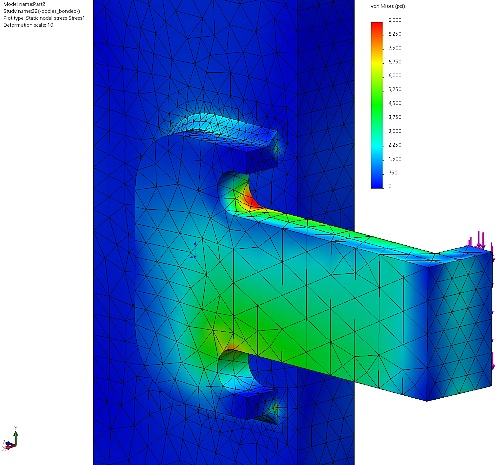
This artificial test problem is used to test run time with contacts in a direct solver.
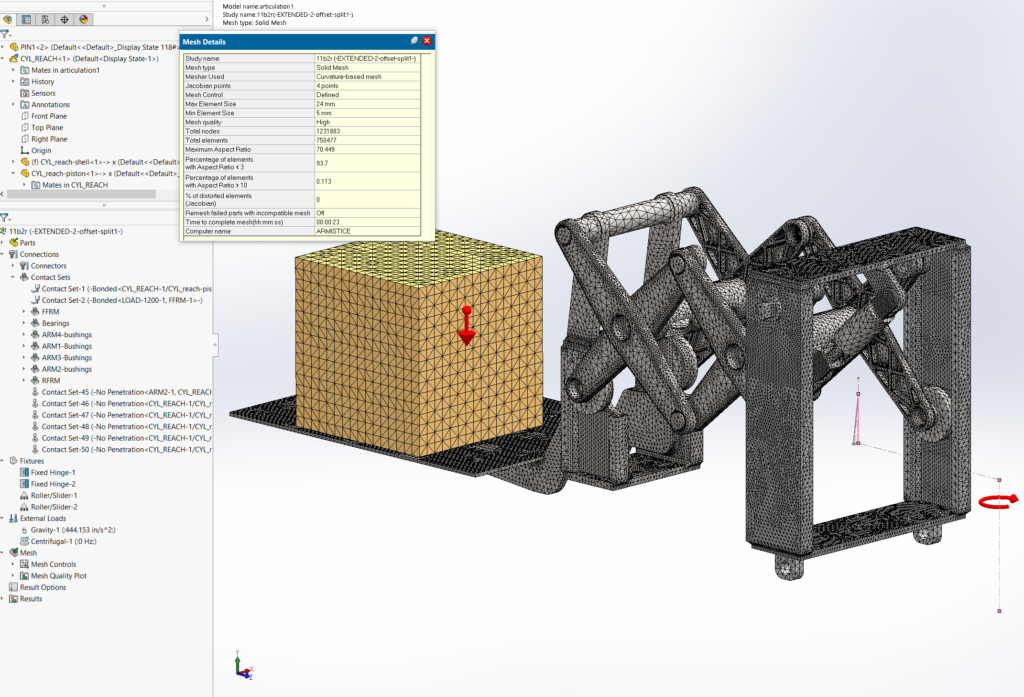
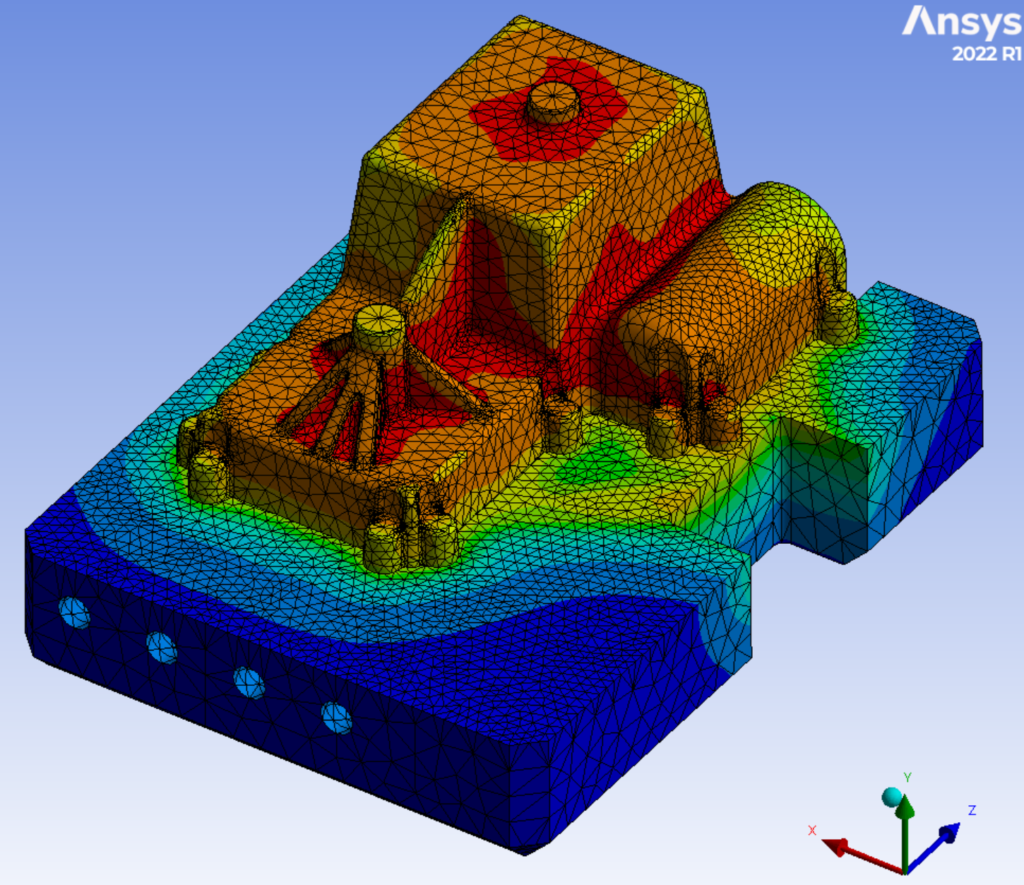
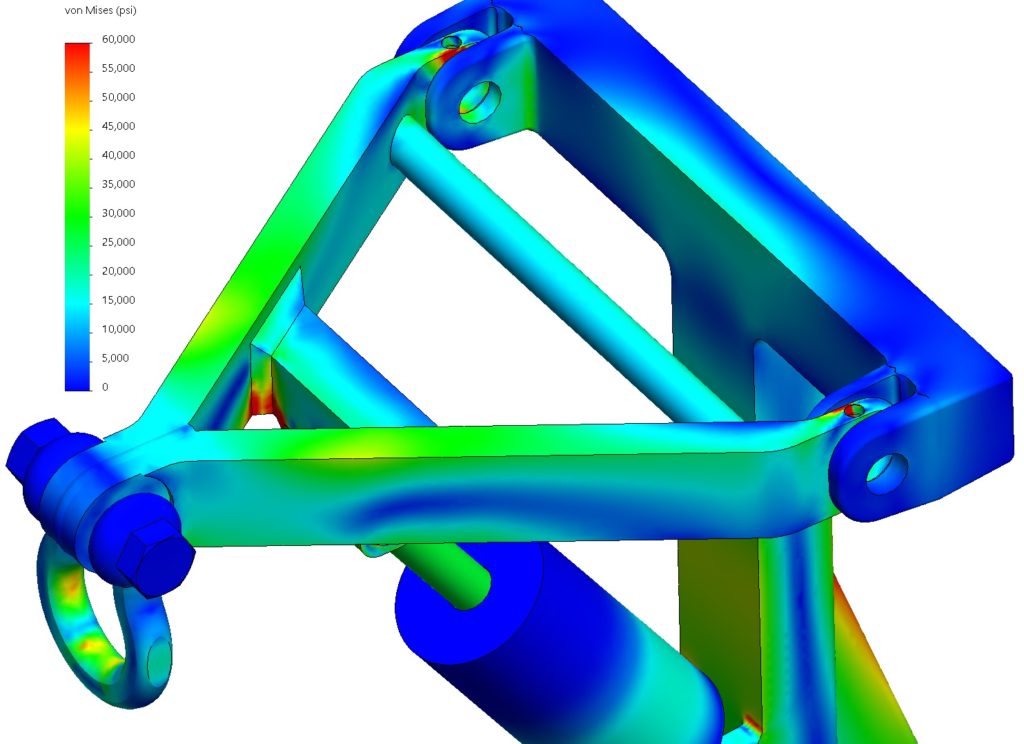
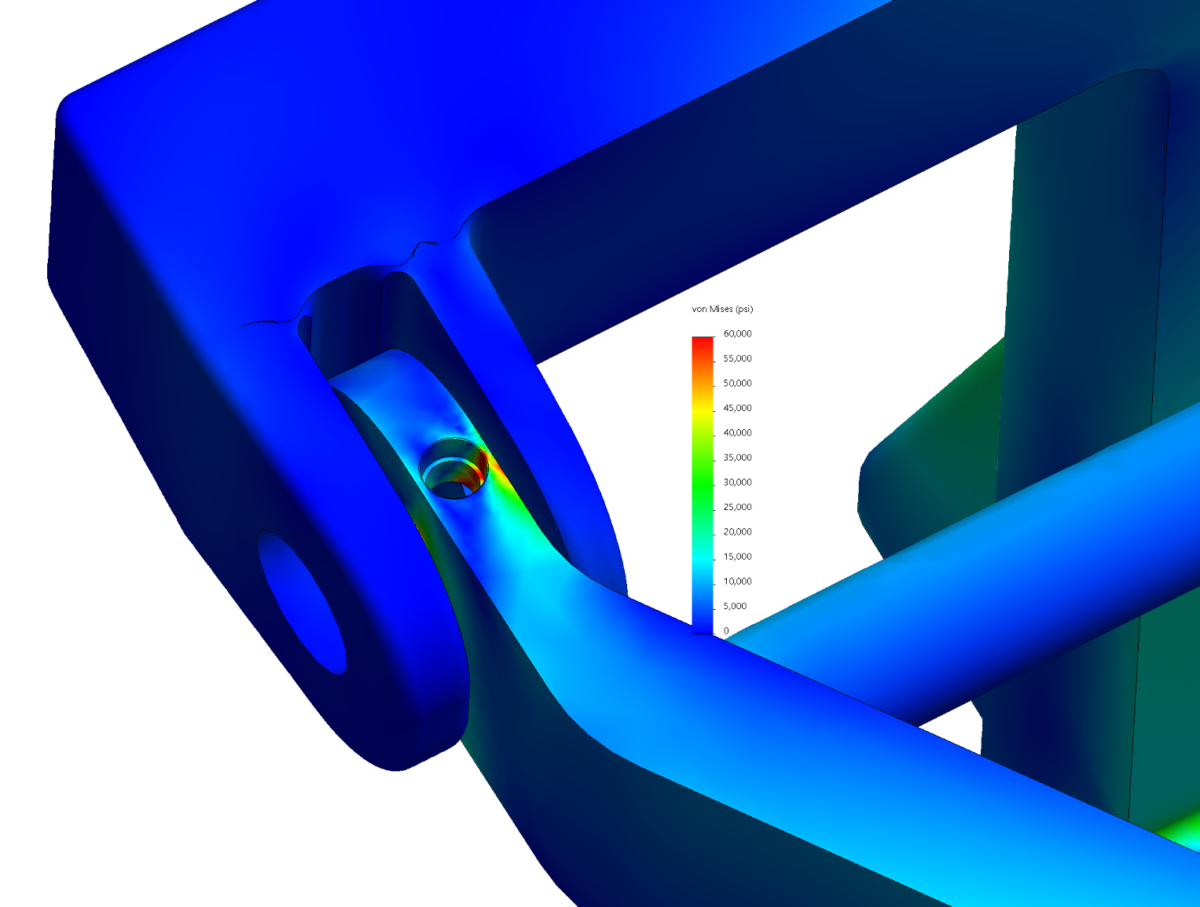
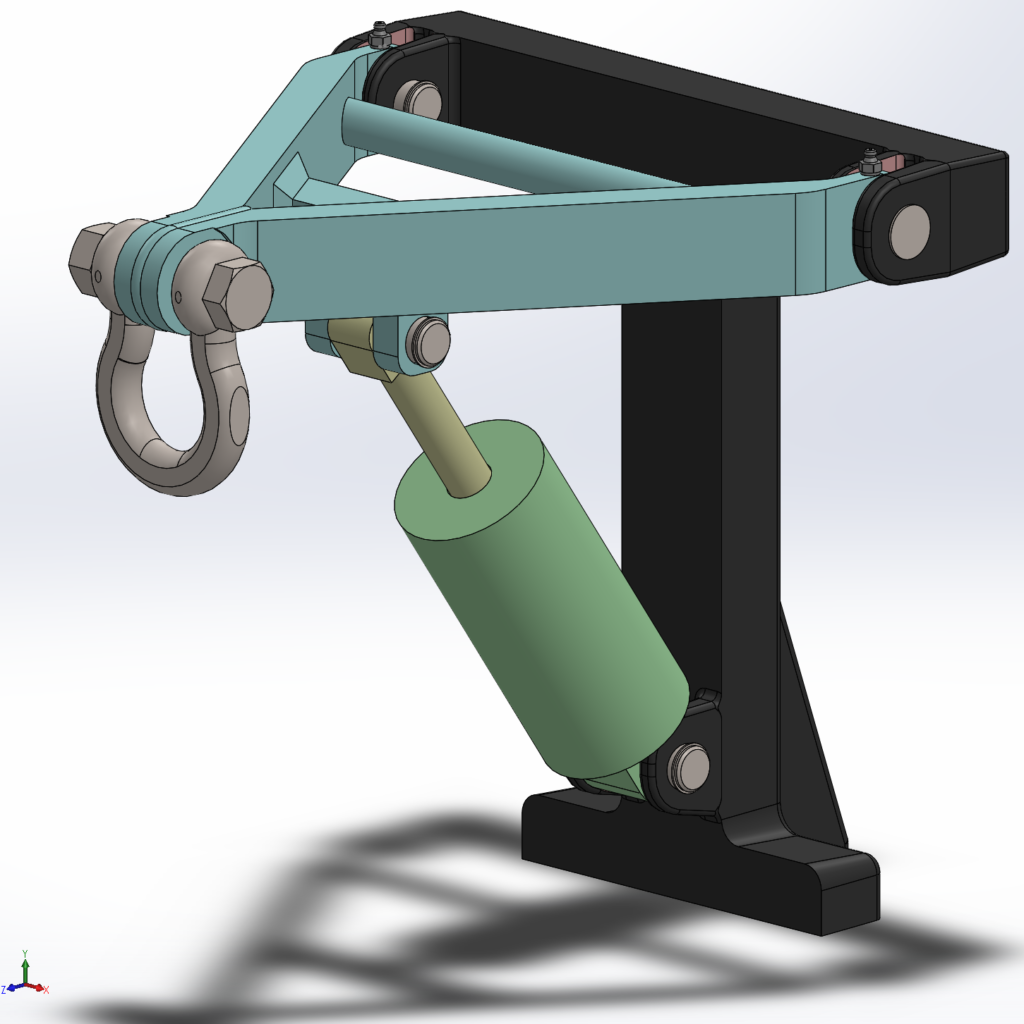
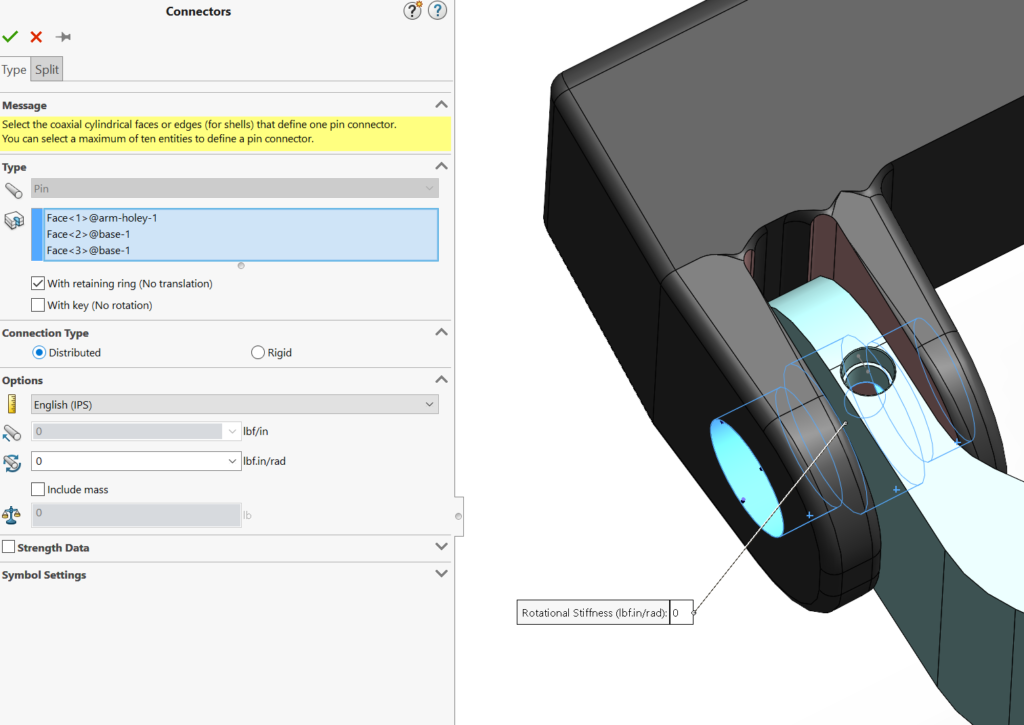
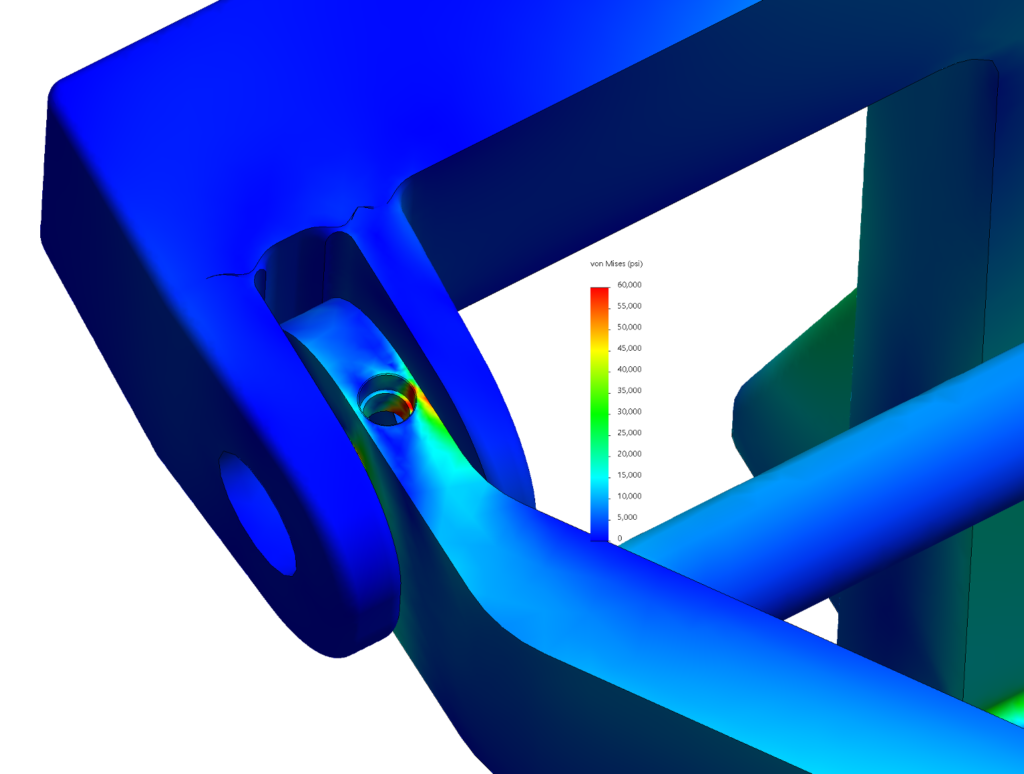
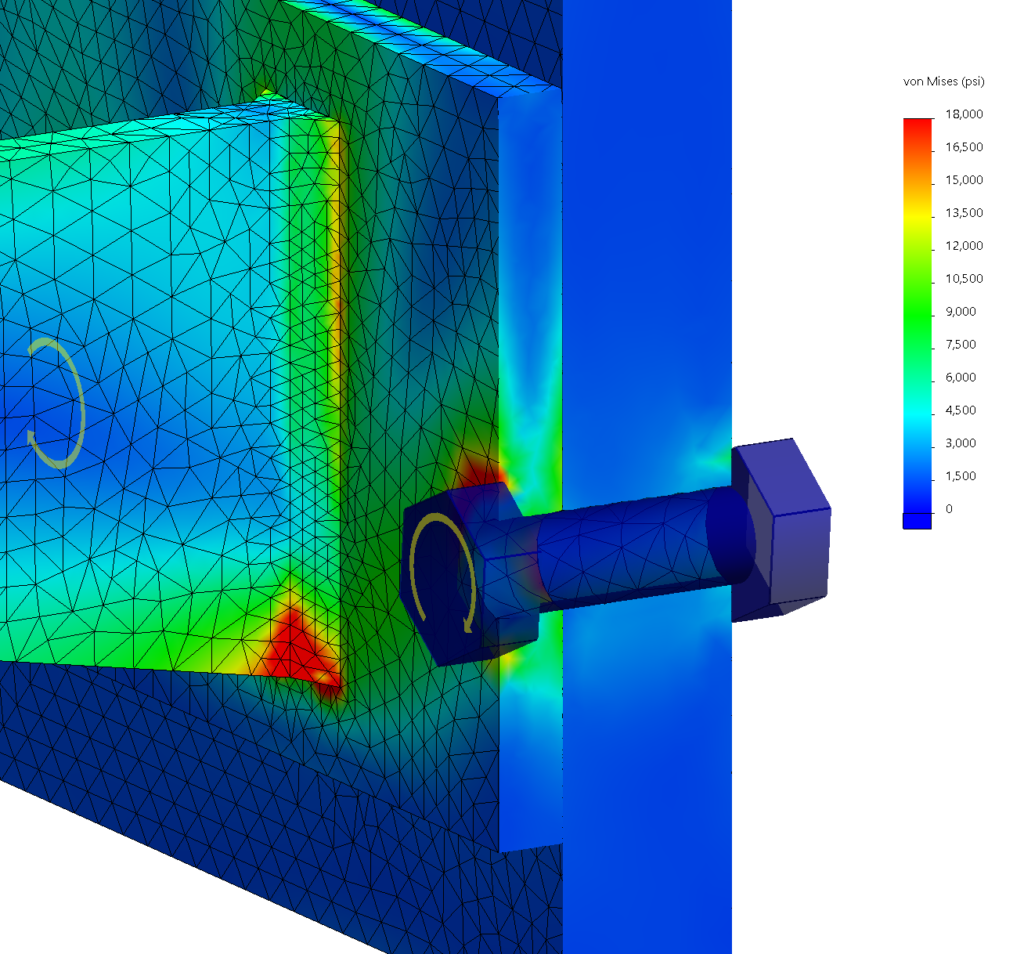
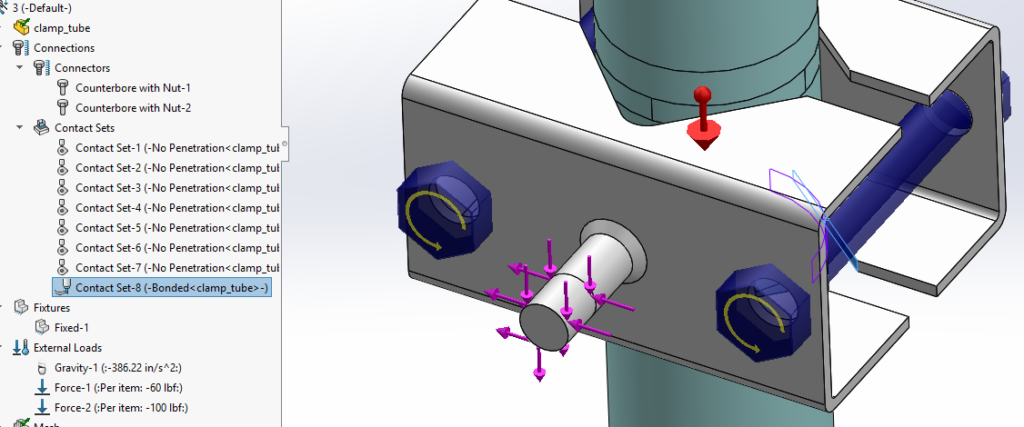
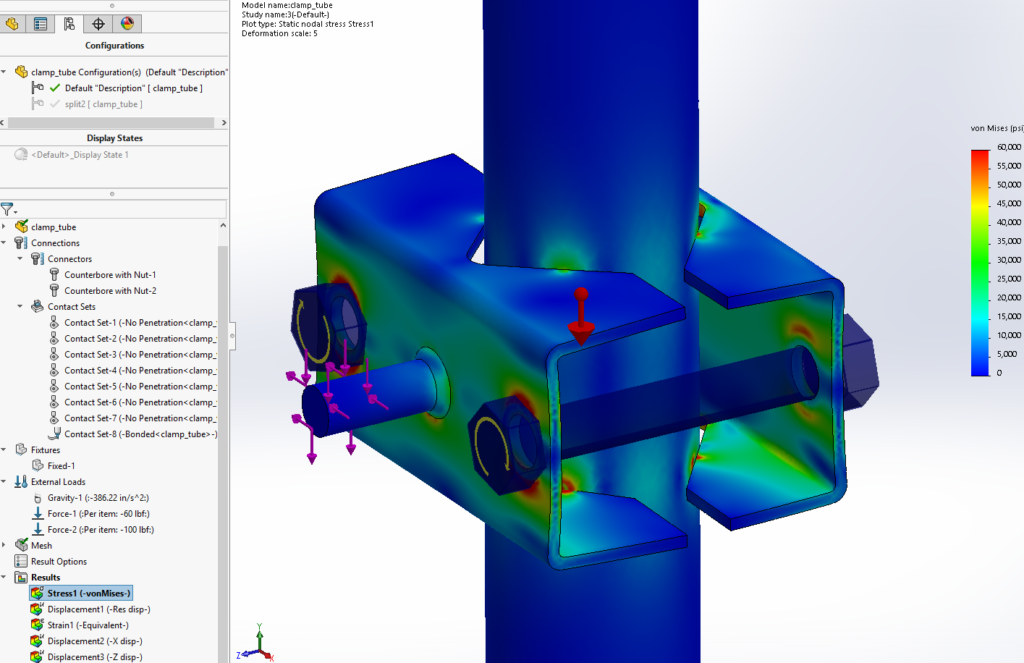
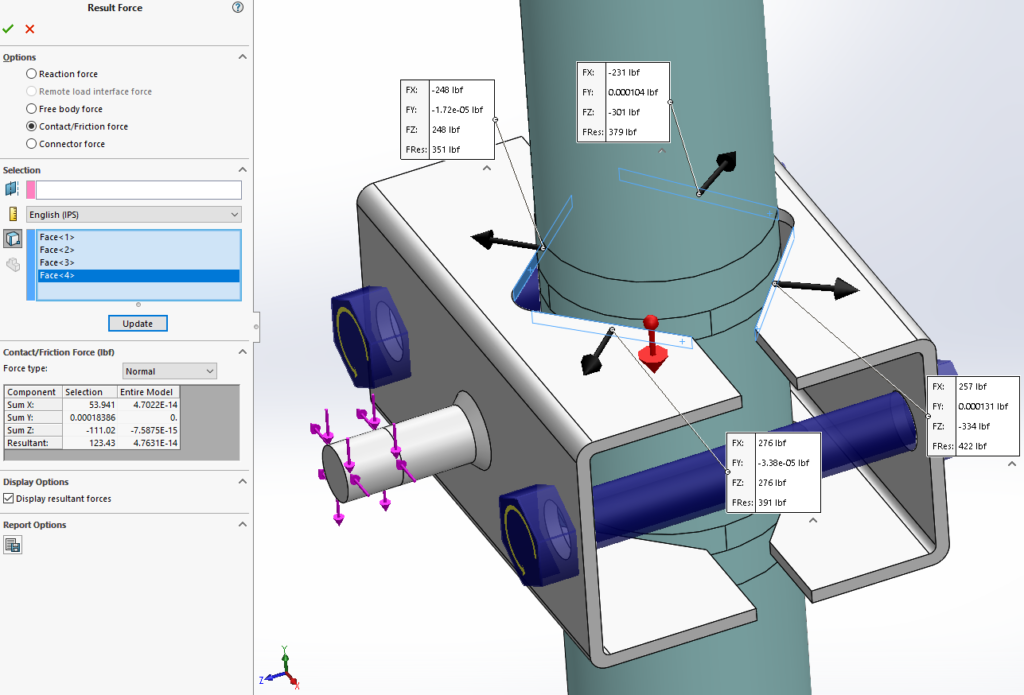
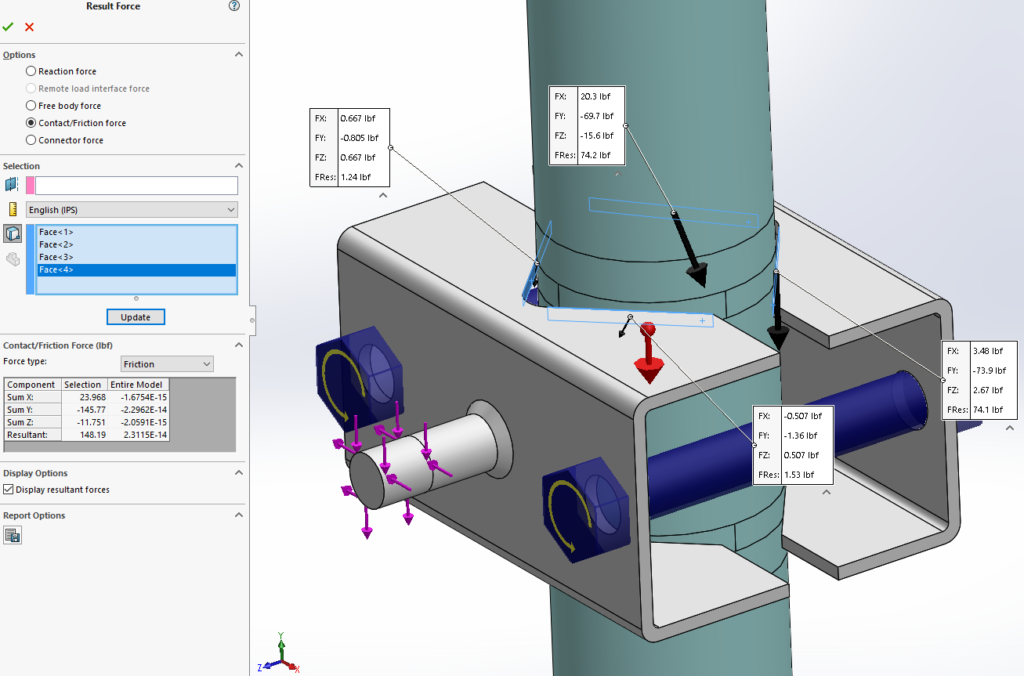
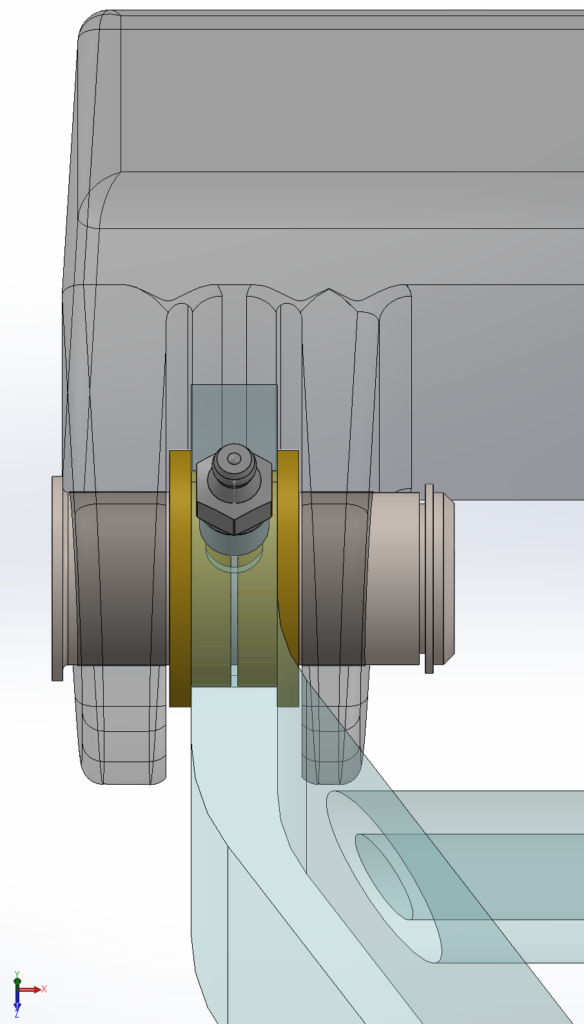
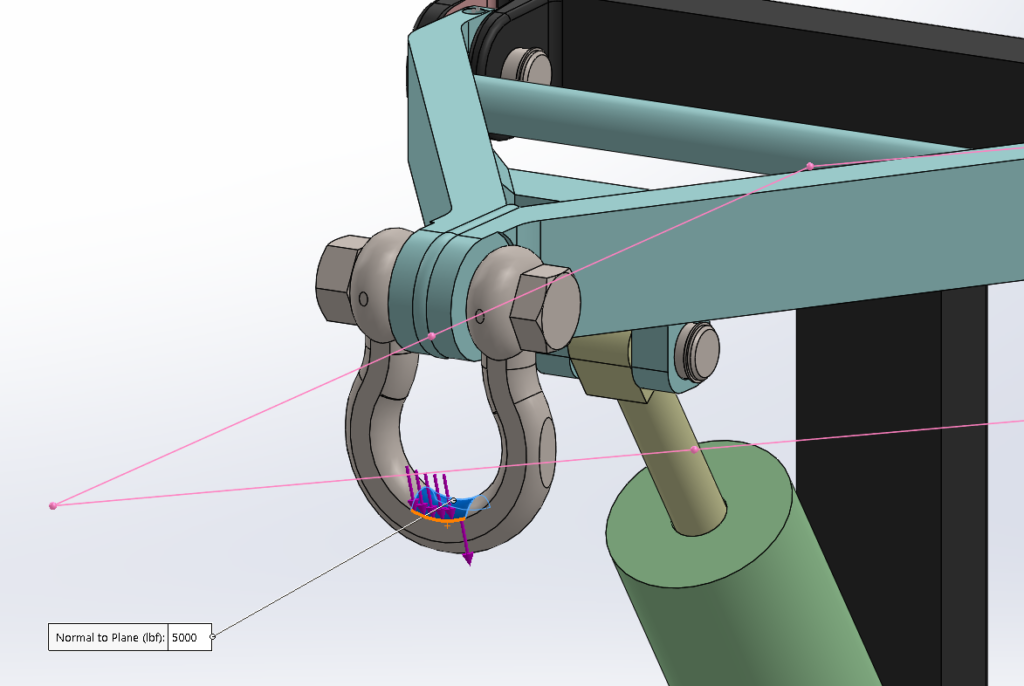
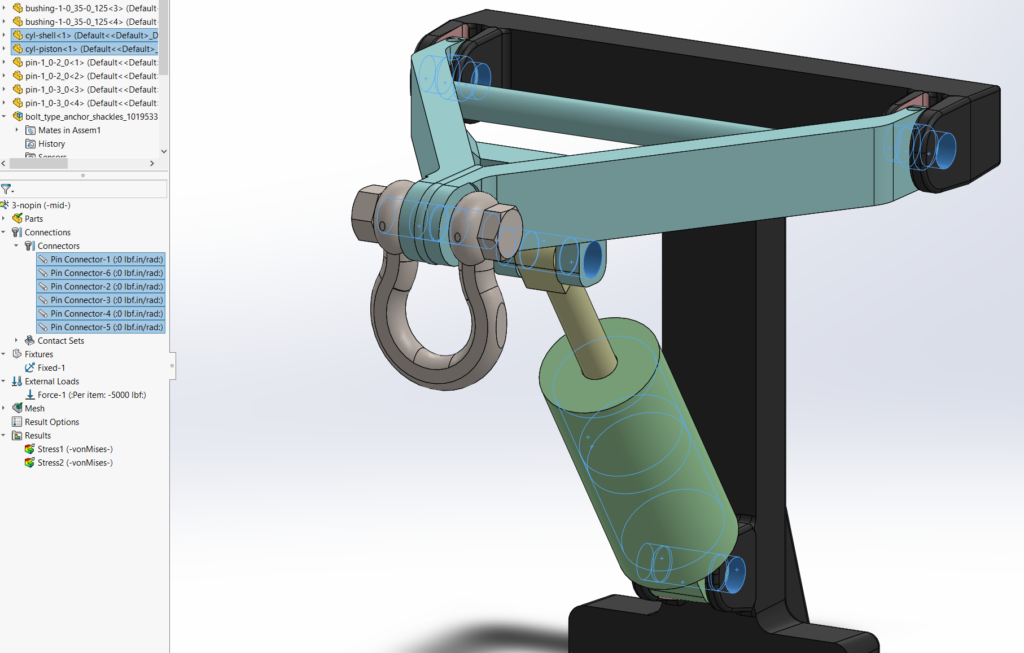
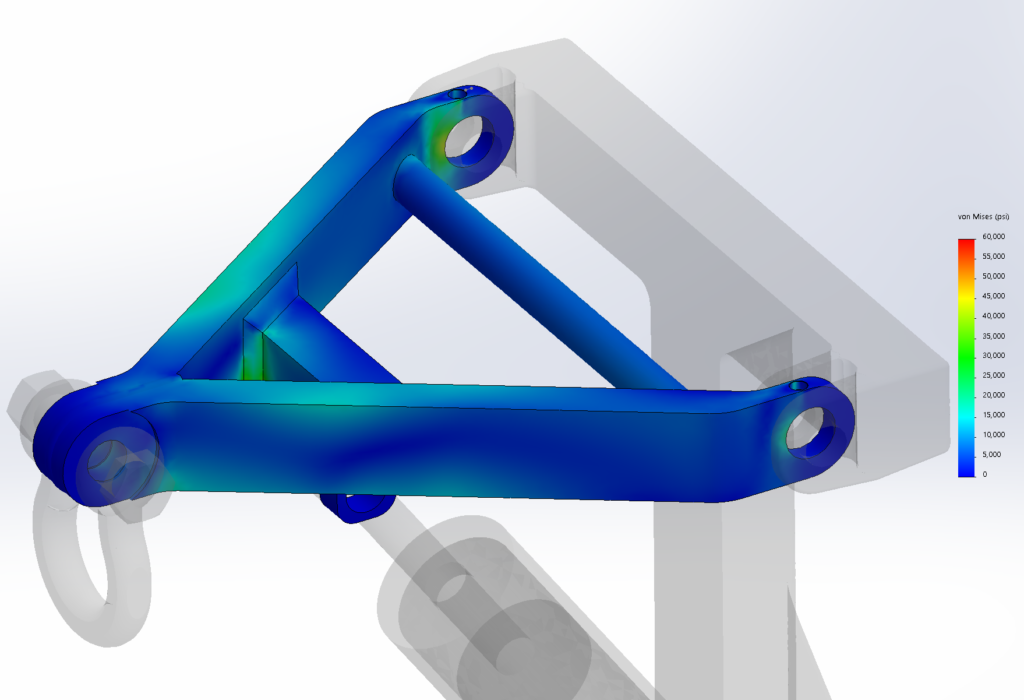
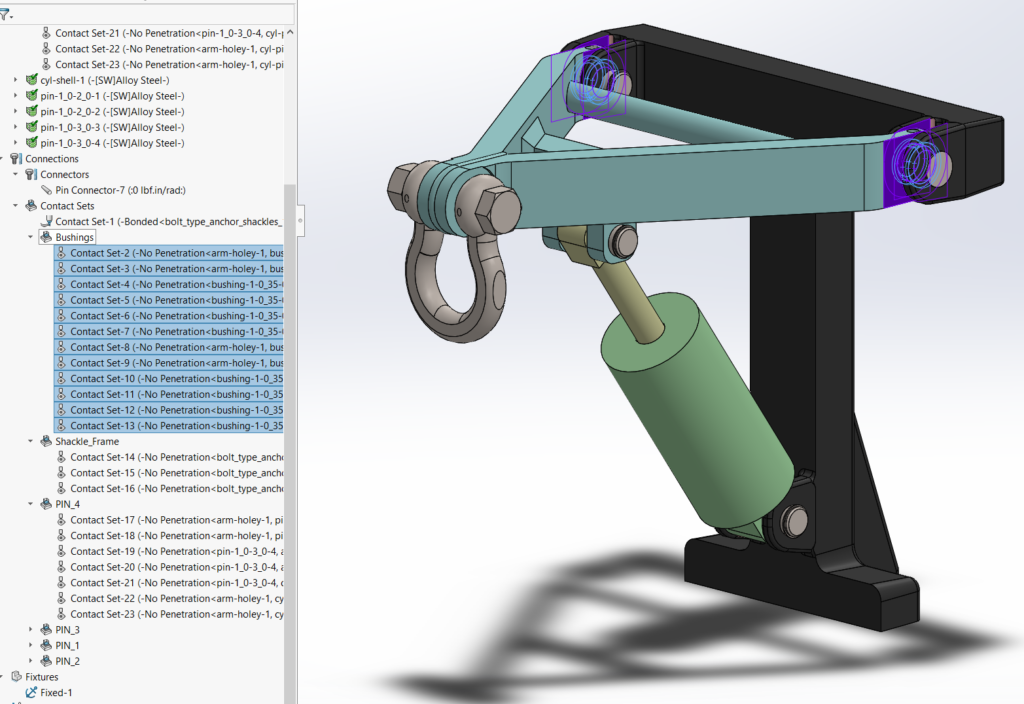
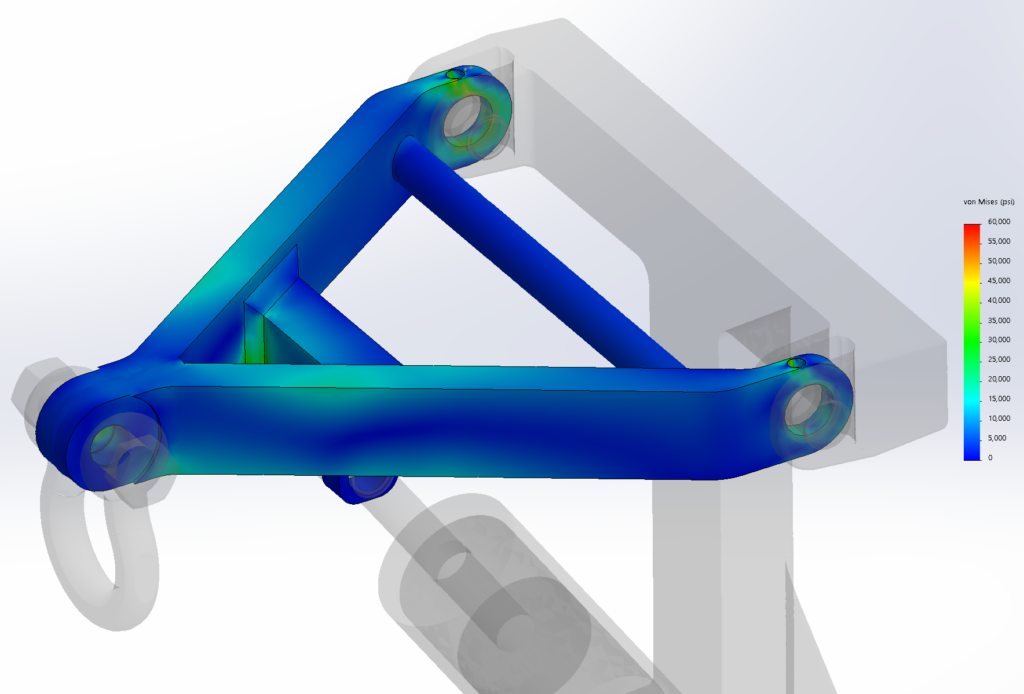
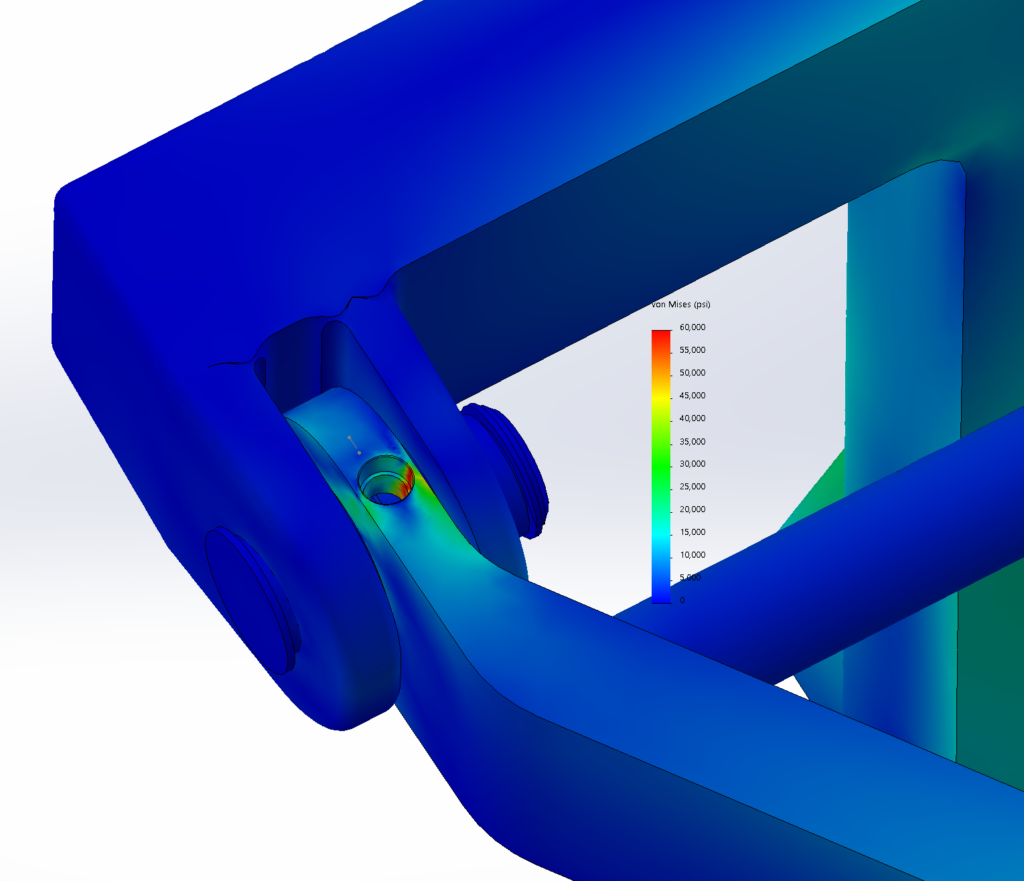
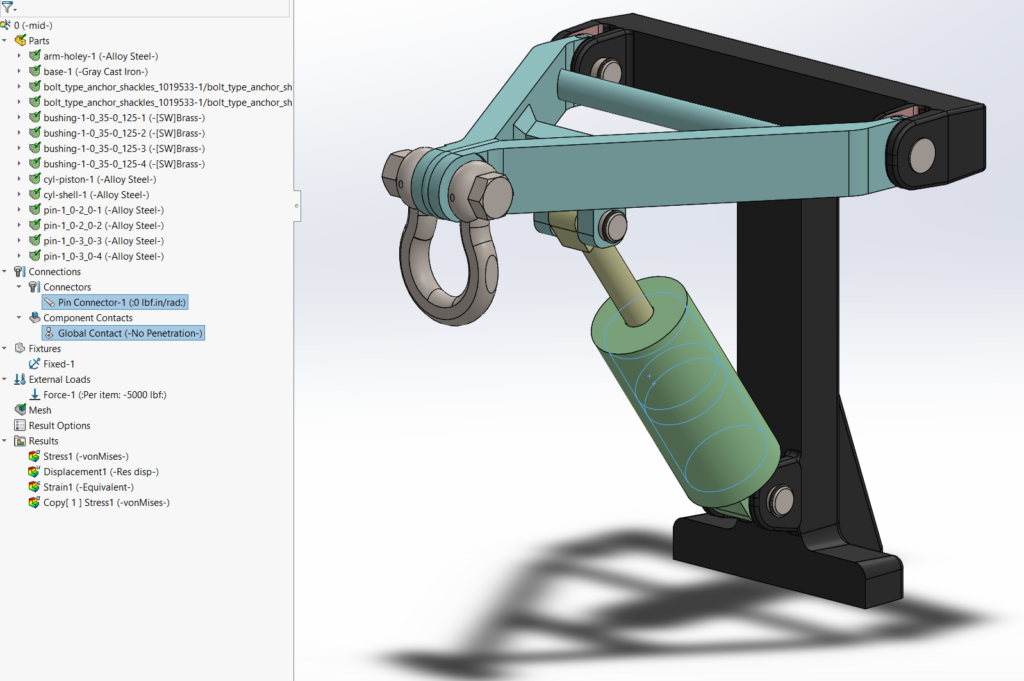
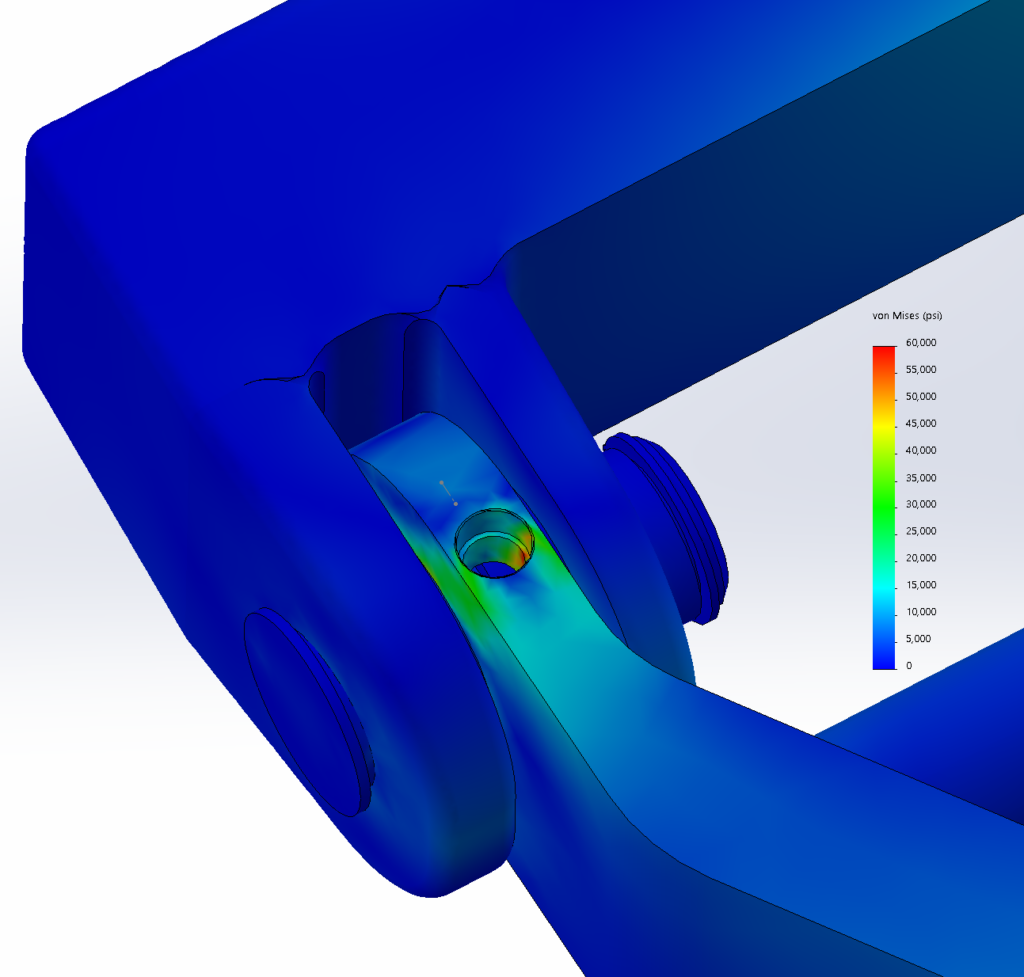
This reach-lift assembly, with an overly fine mesh, gives us the longest run times, with lots of contact and connectors.
The Solidworks Simulation 2020 results are first compared to the available results from 2018.
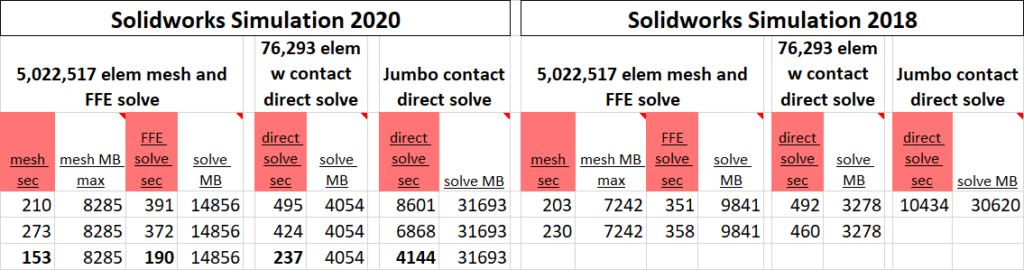
We note that Solidworks 2020 uses a bit more RAM for each operation, we assume in a trade-off for calculation speed. This is reasonable with memory prices dropping logarithmically through recent years (though at this writing DDR5 is still a bit precious).
The processor models aren’t labeled on that table, but one can readily guess that the bottom line is the 12700K. We are very impressed with the results. Solve times are basically halved, using an inexpensive mainstream processor. To visualize this here are more traditional benchmark charts.
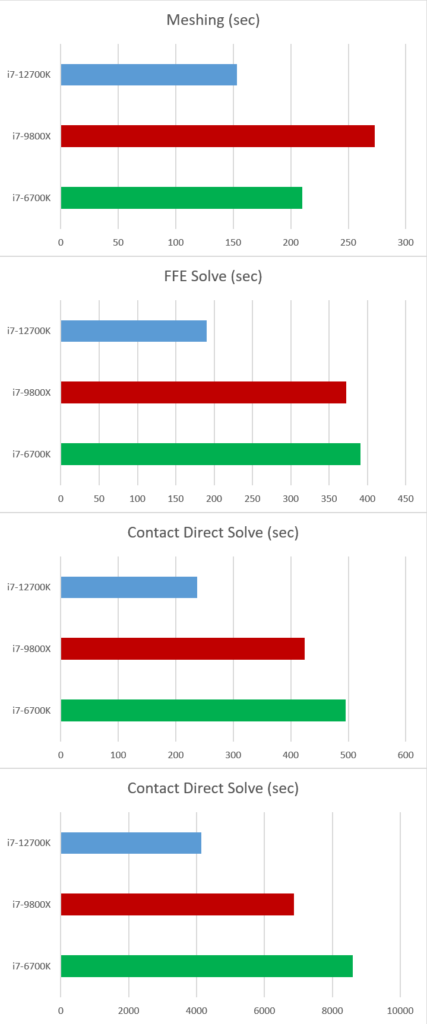
Run times are getting faster, and this is a problem! Our production analyses are getting down to where there isn’t even time to go get a cup of coffee or catch up on important forum posts.
In all seriousness, we’re used to having time to look over new results and integrate them into a running report, possibly discussing updates with a client, before the next iteration runs. We’ll have to work on a new scheme of time management, and throw a bone to the dog who used to get played with more while the computer cranked.
[Notably absent here are results for AMD systems and newer version of Solidworks. We’re still an Intel shop, as other testers have found the AMD architectures poor for Solidworks mechanical sim, though those tests are dated. Solidworks 2021 posed new challenges, with badly documented changes in the interface and some apparent bugs that Dassault has not resolved with us, and we just haven’t tried 2022 yet. If anyone wants to try it, the smaller direct solve study is available here. We’d be happy to see new results.]